 for LLM Development")
Large language models (LLMs) are making lives effortless for people by easing out the workload, automating various tasks, and providing intelligent assistance across multiple domains. While AI innovation has just started, the development of large language models via fine-tuning is crucial to enhancing their performance and effectiveness.
One method for fine-tuning LLMs with constrained data and computational resources is PEFT (Parameter-efficient Fine-tuning). It is an essential tool, and in this blog, we shall discuss its significance for LLM scalability.
The Importance of Fine-Tuning
The intention behind utilizing fine-tuning is that it is easier and cheaper to further the capabilities of a pre-trained base model that has already acquired broad learnings. It becomes especially relevant to train the task at hand than to train a new system from scratch for that specific purpose.
Understanding Problem Statement: Why PEFT?
The first problem is parameter inefficiency, where fine-tuning a pre-trained model for each task requires creating a separate model for each task. It is inefficient in terms of storage, which takes up an enormous amount of space and also wastes a lot of computational power because you’re re-training billions of parameters over and over again.
The second challenge is too much fitting; one problem that comes from this is when a model is trained using smaller datasets. Training a separate model for each task increases the likelihood of other reasons for natural regression failure, like overfitting. This results in inaccurate predictions.
Techniques such as Supervised Fine-tuning (SFT, PEFT) can resolve the problem of creating LLMs that differ greatly from generic models. These techniques make it possible to stand out in specific fields. Fundamental to this approach is the PEFT which fine-tunes only a small subset of the model’s parameters. It introduces additional lightweight parameters instead of updating all the LLM parameters. For improved performance, PEFT focuses on task-specific parameters for domain-specific models that lead to better performance on downstream tasks.
Solutions PEFT offers:
- PEFT is efficient in reducing the computational cost and time required to fine-tune LLMs by training only a small subset of parameters.
- PEFT freezes most of the pre-trained model’s parameters. This creates a lower memory footprint and allows domain experts to train larger models on smaller hardware.
- PEFT helps prevent the model from forgetting previously learned knowledge. It is helpful in preserving the model quality, which can be a common issue with full fine-tuning.
- PEFT is industry-specific because it customizes LLMs for specific tasks, such as medical, legal, or creative writing.
- PEFT applies domain-specific knowledge and is adaptable to specific tasks by fine-tuning relevant data to generate contextually appropriate text.
Key Players and Open-Source Community
Since the LLM landscape is dominated by companies like OpenAI, Google, and Meta, with their proprietary models like GPT-4 and LaMDA, the open-source community is also catching up. Furthermore, the challenges and experiences encountered during AI model development give data scientists and AI developers the scope to make LLM more capable.
How does fine-tuning with PEFT work?
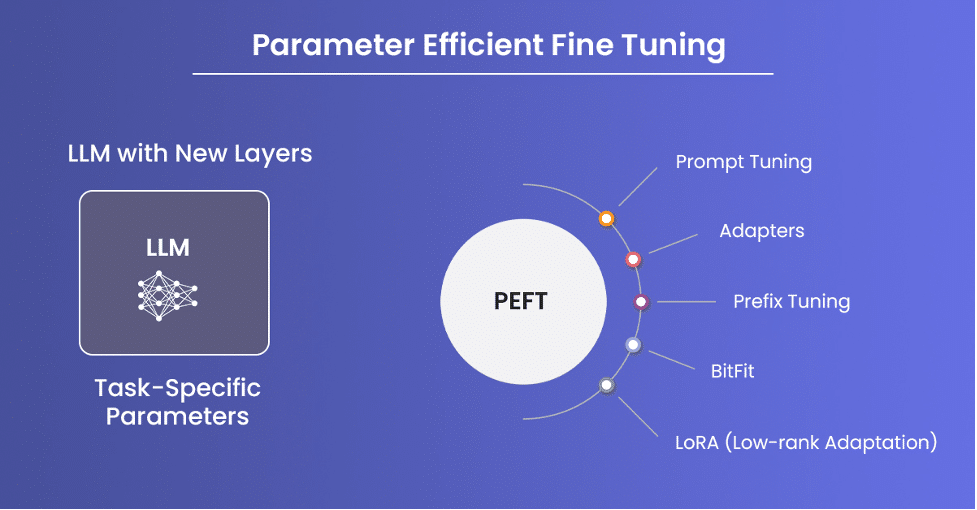
There are some known PEFT approaches utilized by annotation companies. They are as follows:
Prompt Tuning: Optimizes task-specific prompts or embeddings appended to the input instead of fine-tuning the entire model.
Adapters: Small networks are added between layers of the pre-trained model. Only these adapters are trained while the original model weights remain unchanged.
Prefix Tuning: Prepends learnable embeddings to the model’s inputs without changing the model parameters.
BitFit: Updates only the bias terms in the model’s layers.
LoRA (Low-rank Adaptation): This method revises only a fraction or low-rank subset of the model’s weights when fine-tuning while freezing the majority of the parameters.
When to use PEFT?
If you don’t have access to hardware and have limited computational resources, PEFT is considered best for training LLMs. By allowing rapid prototyping, you can experiment quickly with different model architectures and other hyperparameters. As a result, it is able to achieve better performance when it needs to adapt to a particular domain with a smaller amount of training data.
Misleading Business Limitations
The idea that LLM development is not showing full potential because it runs on billions of parameters is misleading about LLM’s true usage and adaptability since what people actually use it for and how they concretize their ideas have nothing to do with creativity.
Because of the number of parameters, LLMs are not bound in any way. In fact, many current state-of-the-art models, such as GPT-4/, have several hundred billion parameters. In order to increase the performance of ML (machine learning) models Like these, the parameters are harmonious with its design and (except for an occasional known bug) have been trained on generally diverse data sets.
The thing is, AI development has just begun, and we have a long way to go. The real limitation often lies in the quality of training data, fine-tuning strategies, and alignment with specific tasks or real-world requirements.
Fine-tuning Strategies
So far, we have discussed the importance of PEFT for fine-tuning and adapting a pre-trained LLM to perform specific tasks by training it further on domain-specific or task-specific data. An effective approach in fine-tuning enhances input prompts and parameters to avoid overfitting risks and also aligns with the resultant output.
Specific Task Alignment
It refers to the alignment that involves training data in sync with the algorithm of the LLM model to meet the specific requirements of the task in a way that is accurate and contextually appropriate. Misalignment, however, leads to outputs that, while coherent, may not be useful or ethical. Notably, methods like reinforcement learning from human feedback (RLHF) and careful prompt engineering are often used to improve task-specific alignment.
Quality of Training Data
Whether an LLM performs well depends on high-quality training data (which needs to be diverse, representative of the use-case scenario, and free from bias). Low-quality or misleading data can lead to inaccurate, biased, or incomplete outputs. Herein, annotating companies make sure the data is well-curated, clean, and correct for the intended applications.
When it comes to LLMs’ potential, there are many possible applications and business opportunities. However, in addition to the size of the model and training difficulties that may be involved, it is more important how these models are adapted, deployed, used, and fine-tuned for specific task requirements.
The Objective of LLMs for Business
Large Language Models (LLMs) show promising results in customer service, content creation, and powering intelligent chatbots and virtual assistants, which expedites human work. Furthermore, they deem it helpful in analyzing vast datasets and extracting valuable insights through the natural language processing (NLP) approach.
The current objective is to fine-tune LLMs to make these models truly remarkable. There are numerous reasons for fine-tuning:
- Fine-tuning trains LLMs on language, terminology, nuances and their ability to create relevant and accurate output.
- LLMs that are fine-tuned prevent biases and make the model more fair.
- Though LLMs are known for being generic models, fine-tuning can tailor them for specific tasks like summarization, translation, or code generation.
- Fine-tuning with PEFT improves the utility of LLMs by aligning the model in terms of coherence, relevance, accuracy, etc., like metrics.
What’s next?
From traditional full fine-tuning involving small adjustments in LLM training to modern fine-tuning with PEFT, progress is being made toward making AI/ML models resource-efficient and customizable for specific tasks. PEFT us definitely transforming the AI model while keeping computational and storage requirements low.
The future of LLMs seems bright, with exciting new revenue opportunities for businesses. We can also expect to witness LLMs that can handle even more complex and nuanced texts.